

Authors:
(1) Kedan Li, University of Illinois at Urbana-Champaign;
(2) Min Jin Chong, University of Illinois at Urbana-Champaign;
(3) Jingen Liu, JD AI Research;
(4) David Forsyth, University of Illinois at Urbana-Champaign.
Table of Links
4. Experiments
4.1 Datasets
The VITON dataset [17] contains pairs of product image (front-view, laying flat, white background) and studio images, 2D pose maps and pose key-points. It has been used by many works [45,11,15,53,24,22,2,37]. Some works [47,15,13,51] on multi-pose matching used DeepFashion [33] or MVC [32] and other self-collected datasets [12,21,47,55]. These datasets have the same product worn by multiple people, but do not have a product image, therefore not suitable for our task.
The VITON dataset only has tops. This likely biases performance up, because (for example): the drape of trousers is different from the drape of tops; some garments (robes, jackets, etc.) are often unzipped and open, creating warping issues; the drape of skirts is highly variable, and depends on details like pleating, the orientation of fabric grain and so on. To emphasize these real-world problem, we collected a new dataset of 422,756 fashion products through web-scraping fashion e-commerce sites. Each product contains a product image (front-view, laying flat, white background), a model image (single person, mostly front-view), and other metadata. We use all categories except shoes and accessories, and group them into four types (top, bottoms, outerwear, or all-body). Type details appear in the supplementary materials.
We randomly split the data into 80% for training and 20% for testing. Because the dataset does not come with segmentation annotation, we use Deeplab v3 [6] pre-trained on ModaNet dataset [56] to obtain the segmentation masks for model images. A large portion of the segmentation masks are noisy, which further increases the difficulty (see Supplementary Materials).
4.2 Training Process
We train our model on our newly collected dataset and the VITON dataset [17] to facilitate comparison with prior work. When training our method on VITON dataset, we only extract the part of the 2D pose map that corresponds to the product to obtain segmentation mask, and discard the rest. The details of the training procedure is in Supplementary Materials.
We also attempted to train prior works on our dataset. However, prior work [45,17,11,15,53,24,22,13,47,51,7,37] require pose estimation annotations which is not available in our dataset. Thus, we only compare with prior work on the VITON dataset.
4.3 Quantitative Evaluation
Quantitative comparison with state of the art is difficult. Reporting the FID in other papers is meaningless, because the value is biased and the bias depends on the parameters of the network used [9,37]. We use the FID∞ score, which is unbiased. We cannot compute FID∞ for most other methods, because results have not been released; in fact, recent methods (eg [15,53,24,24,42,22,2]) have not released an implementation. CP-VTON [45] has, and we use this as a point of comparison.
Most evaluation is qualitative, and others [24,37] also computed the FID score on the original test set of VITON, which consists of only 2,032 synthesized pairs. Because of the small dataset, this FID score is not meaningful. The variance arising from the calculation will be high which leads to a large bias in the FID score, rendering it inaccurate. To ensure an accurate comparison, we created a larger test set of synthesized 50,000 pairs through random matching, following the procedure of the original work [17]. We created new test sets using our shape matching model by selecting the top 25 nearest neighbors in the shape embedding space for every item in the original test set. We produce two datasets each of 50,000 pairs using colored image and grayscale images to compute the shape embedding. The grayscale ablation tells us whether the shape embedding looks at color features.
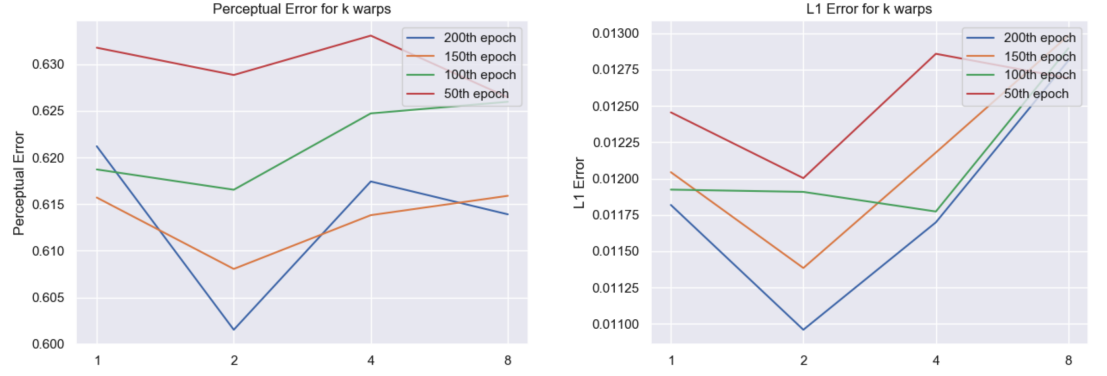
The number of warps is chosen by computing the L1 error and Perceptual error (using VGG19 pre-trained on ImageNet) using warpers with different k on the test set of our dataset. Here the warper is evaluated by mapping a product to a model wearing that product. As shown in figure 5, k = 2 consistently out-performs k = 1. However, having more than two warps also reduce performance using the current training configuration, possibly due to overfitting.
We choose β by training a single warp model with different β values using 10% of the dataset, then evaluating on test. Table 1 shows that a β that is too large or two small cause the performance to drop. β = 3 happens to be the best, and therefore is adopted. Qualitative comparison are available in supplementary materials.

With this data, we can compare CP-VTON, our method using a single warp (k = 1), and two warps (k = 2), and two warp blended. The blended model takes in the average of two warps instead of the concatenation. Results appear in Table 4.3. We find:
– for all methods, choosing the model gets better results;
– there is little to choose between color and grayscale matching, so the match attends mainly to garment shape;
– having two warpers is better than having one;
– combining with a u-net is much better than blending.
We believe that quantitative results understate the improvement of using more warpers, because the quantitative measure is relatively crude. Qualitative evidence supports this (figure 7).
4.4 Qualitative Results
We have looked carefully for matching examples in [15,24,53,37] to produce qualitative comparisons. Comparison against MG-VTON [12] is not applicable, as the work did not include any fixed-pose qualitative example. Note that the comparison favors prior work because our model trains and tests only using the region corresponding to the garment in the 2D pose map while prior work uses the full 2D pose map and key-point pose annotations.
Generally, garment transfer is hard, but modern methods now mainly fail on details. This means that evaluating transfer requires careful attention to detail. Figure 6 shows some comparisons. In particular, attending to image detail around boundaries, textures, and garment details exposes some of the difficulties in the task. As shown in Figure 6 left, our method can handle complicated texture robustly (col. a, c) and preserve details of the logo accurately (col. b, e, f, g, i). The examples also show clear difference between our inpainting-based method and prior work – our method only modifies the area where the original cloth is


presented. This property allows us to preserve the details of the limb (col. a, d, f, g, h, j) and other clothing items (col. a, b) better than most prior work. Some of our results (col. c, g) show color artifacts from the original cloth on the boundary, because the edge of the pose map is slightly misaligned (imperfect segmentation mask). This confirms that our method rely on fine-grain segmentation mask to produce high quality result. Some pairs are slightly mis-matched in shape(col. d, h). This will rarely occur with our method if the test set is constructed using the shape embedding. Therefore, our method does not attempt to address it.
Two warps are very clearly better than one (Figure 7), likely because the second warp can fix the alignment and details that single warp model fails to address. Particular improvements occur for unbuttoned/unzipped outerwear and for product images with tags. These improvement may not be easily captured by quantitative evaluation because the differences in pixel values are small.

We attempted to train the geometric matching module (using TPS transform) to create warps on our dataset, as it was frequently adopted by prior work [17,45,11]. However, TPS transform failed to adapt to partitions and significant occlusions (examples in Supplementary Materials).
4.5 User Study
We used a user study to check how often users could identify synthesized images. A user is asked whether an image of a model wearing a product (which is shown) is real or synthesized. Display uses the highest possible resolution (512x512), as in figure 8.
We used examples where the mask is good, giving a fair representation of the top 20 percentile of our results. Users are primed with two real vs. fake pairs before the study. Each participant is then tested with 50 pairs of 25 real and


25 fake, without repeating products. We test two populations of users (vision researchers, and randomly selected participants).
Mostly, users are fooled by our images; there is a very high false-positive (i.e. synthesized image marked real by a user) rate (table 3). Figure 8 shows two examples of synthesized images that 70% of the general population reported as real. They are hard outerwear examples with region partition and complex shading. Nevertheless, our method managed to generate high quality synthesis. See supplementary material for all questions and complete results of the user study.
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.