

Authors:
(1) Kedan Li, University of Illinois at Urbana-Champaign;
(2) Min Jin Chong, University of Illinois at Urbana-Champaign;
(3) Jingen Liu, JD AI Research;
(4) David Forsyth, University of Illinois at Urbana-Champaign.
Table of Links
Abstract
A virtual try-on method takes a product image and an image of a model and produces an image of the model wearing the product. Most methods essentially compute warps from the product image to the model image and combine using image generation methods. However, obtaining a realistic image is challenging because the kinematics of garments is complex and because outline, texture, and shading cues in the image reveal errors to human viewers. The garment must have appropriate drapes; texture must be warped to be consistent with the shape of a draped garment; small details (buttons, collars, lapels, pockets, etc.) must be placed appropriately on the garment, and so on. Evaluation is particularly difficult and is usually qualitative.
This paper uses quantitative evaluation on a challenging, novel dataset to demonstrate that (a) for any warping method, one can choose target models automatically to improve results, and (b) learning multiple coordinated specialized warpers offers further improvements on results. Target models are chosen by a learned embedding procedure that predicts a representation of the products the model is wearing. This prediction is used to match products to models. Specialized warpers are trained by a method that encourages a second warper to perform well in locations where the first works poorly. The warps are then combined using a U-Net. Qualitative evaluation confirms that these improvements are wholesale over outline, texture shading, and garment details.
Keywords: Fashion, Virtual try-on, Image generation, Image warping
1. Introduction
E-commerce means not being able to try on a product, which is difficult for fashion consumers [44]. Sites now routinely put up photoshoots of models wearing products, but volume and turnover mean doing so is very expensive and time consuming [34]. There is a need to generate realistic and accurate images of fashion models wearing different sets of clothing. One could use 3D models of posture [8,14]. The alternative – synthesize product-model images without 3D measurements [17,45,39,11,15] – is known as virtual try-on. These methods usually consist of two components: 1) a spatial transformer to warp the product
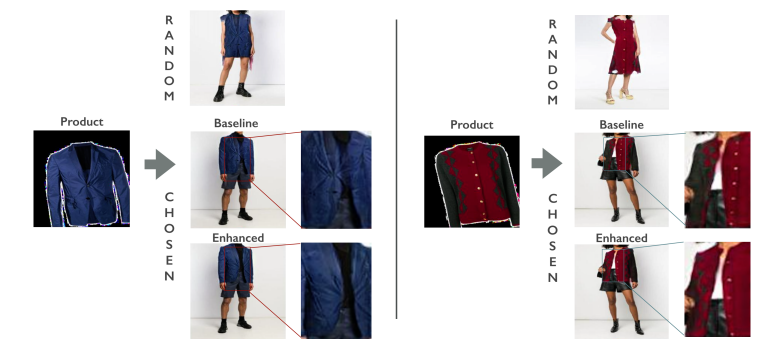
image using some estimate of the model’s pose and 2) an image generation network that combines the coarsely aligned, warped product with the model image to produce a realistic image of the model wearing the product.
It is much easier to transfer with simple garments like t-shirts, which are emphasized in the literature. General garments (unlike t-shirts) might open in front; have sophisticated drapes; have shaped structures like collars and cuffs; have buttons; and so on. These effects severely challenge existing methods (examples in Supplementary Materials). Warping is significantly improved if one uses the product image to choose a model image that is suited to that garment (Figure 1).
At least in part, this is a result of how image generation networks are trained. We train using paired images – a product and a model wearing a product [17,45,53]. This means that the generation network always expects the target image to be appropriate for the product (so it is not trained to, for example, put a sweater onto a model wearing a dress, Figure 1). An alternative is to use adversarial training [11,12,38,13,37]; but it is hard to preserve specific product details (for example, a particular style of buttons; a decal on a t-shirt) in this framework. To deal with this difficulty, we learn an embedding space for choosing product-model pairs that will result in high-quality transfers (Figure 2). The embedding learns to predict what shape a garment in a model image would take if it were in a product image. Products are then matched to models wearing similarly shaped garments. Because models typically wear many garments, we use a spatial attention visual encoder to parse each category (top, bottom, outerwear, all-body, etc.) of garment and embed each separately.
Another problem arises when a garment is open (for example, an unbuttoned coat). In this case, the target of the warp might have more than one connected component. Warpers tend to react by fitting one region well and the other poorly, resulting in misaligned details (the buttons of Figure 1). Such errors may make little contribution to the training loss, but are very apparent and are considered severe problems by real users. We show that using multiple coordinated specialized warps produces substantial quantitative and qualitative improvements in warping. Our warper produces multiple warps, trained to coordinate with each other. An inpainting network combines the warps and the masked model, and creates a synthesized image. The inpainting network essentially learns to choose between the warps, while also provides guidance to the warper, as they are trained jointly. Qualitative evaluation confirms that an important part of the improvement results from better predictions of buttons, pockets, labels, and the like.
We show large scale quantitative evaluations of virtual try-on. We collected a new dataset of 422,756 pairs of product images and studio photos by mining fashion e-commerce sites. The dataset contains multiple product categories. We compare with prior work on the established VITON dataset [17] both quantitatively and qualitatively. Quantitative result shows that choosing the productmodel pairs using our shape embedding yields significant improvements for all image generation pipelines (table 4.3). Using multiple warps also consistently outperform the single warp baseline, demonstrated through both quantitative (table 4.3, figure 5) and qualitative (figure 7) results. Qualitative comparison with prior work shows that our system preserves the details of both the tochange garment and the target model more accurately than prior work. We conducted a user study simulating the cost for e-commerce to replace real model with synthesized model. Result shows 40% of our synthesized model are thought as real models.
As a summary of our contributions:
– we introduce a matching procedure that results in significant qualitative and quantitative improvements in virtual try-on, whatever warper is used.
– we introduce a warping model that learns multiple coordinated-warps and consistently outperforms baselines on all test sets.
– our generated results preserve details accurately and realistically enough to make shoppers think that some of the synthesized images are real.
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.